Automatic vulnerability intelligence in GCVE: why this matters even more now
On April 15, 2026, NIST announced a major operational shift for the NVD: instead of enriching every CVE with the same level of analysis, it will now prioritize vulnerabilities that are already known to be exploited, relevant to the U.S. federal government, or part of critical software. The rest will still be tracked, but not systematically enriched with the metadata many defenders have become used to, including severity scoring.
This is not a criticism of NIST. It is a recognition of reality.
The number of vulnerabilities keeps growing, the diversity of sources keeps expanding, and the old centralized enrichment model is reaching its practical limits. What we are seeing is not a temporary bottleneck. It is a structural change in the vulnerability ecosystem.
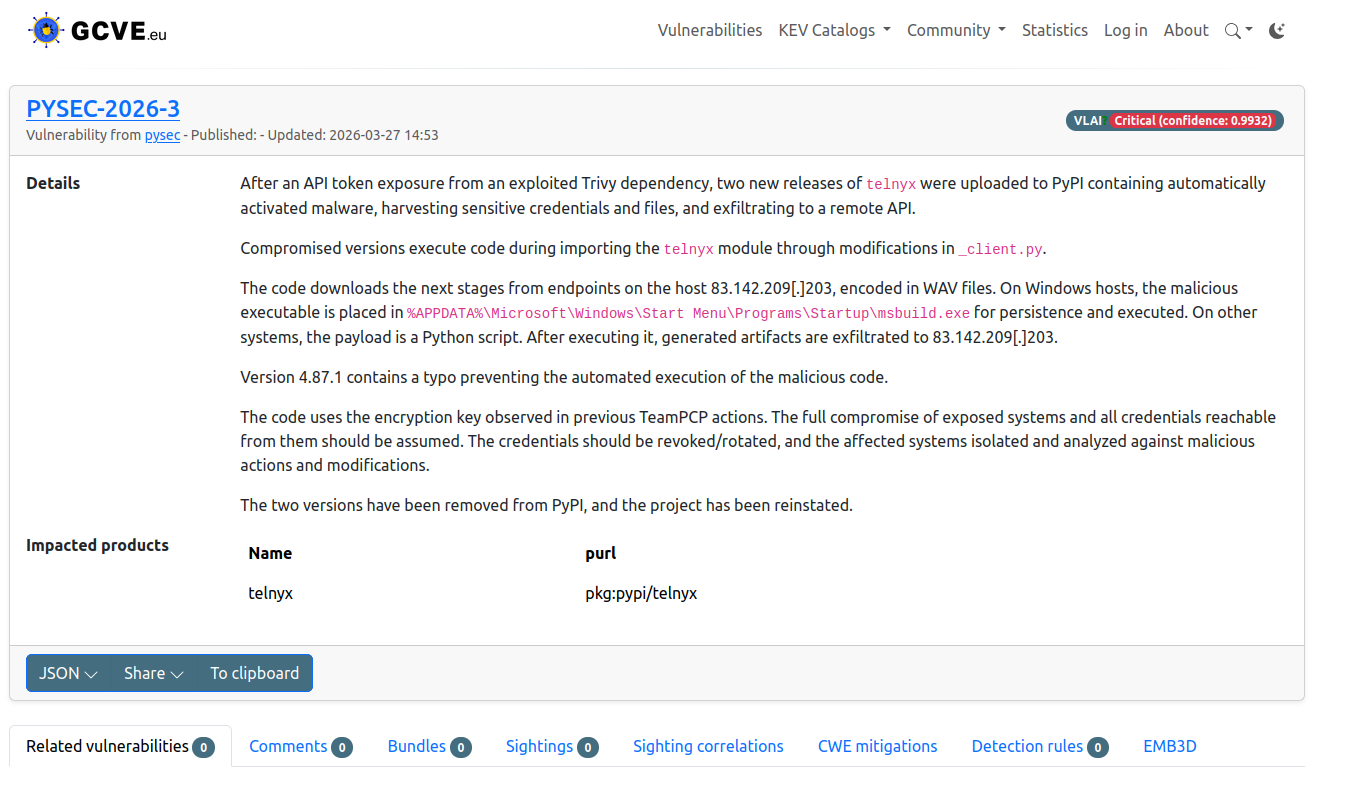
GCVE is not only designed for distributed vulnerability publication and correlation across multiple sources. It already provides automatic vulnerability classification capabilities through the broader Vulnerability-Lookup ecosystem. In particular, GCVE can rely on VL-AI to automatically estimate vulnerability severity from historical data, giving defenders an immediate first-pass assessment even when no manually curated score is yet available.
A vulnerability ecosystem that cannot depend on a single enrichment pipeline
For years, many workflows have assumed that one central database would receive CVE records, normalize them, enrich them, score them, and provide a clean answer to the rest of the ecosystem.
That model is under pressure.
The vulnerability landscape is now fed by many parallel sources:
- vendor advisories
- CSAF providers
- national vulnerability databases
- coordinated disclosure processes
- exploit intelligence feeds
- community-driven sources
- alternative numbering and publication workflows
A modern vulnerability system must therefore do more than mirror identifiers. It must correlate information across sources, preserve provenance, and support automation where humans can no longer keep up at scale.
GCVE was built with that distributed reality in mind.
GCVE is distributed by design
The Global CVE Allocation System (GCVE) is not just another identifier scheme. It is part of a broader ecosystem designed to support decentralized vulnerability publication and correlation.
In practice, this means:
- multiple sources can publish and maintain vulnerability information
- records can be synchronized instead of funneled through a single central bottleneck
- identifiers and related records can be correlated across ecosystems
- consumers get a broader and more resilient view of vulnerability intelligence
This approach is strongly aligned with how the ecosystem already behaves in the real world: information appears in different places, at different times, with different levels of precision and completeness.
The role of GCVE is not to pretend that one source will always be complete. The role of GCVE is to help build a global overview from all relevant sources.
Correlation matters more when enrichment becomes selective
Once enrichment is no longer guaranteed everywhere, correlation becomes critical.
A vulnerability may have:
- a reserved or partial identifier in one system
- a vendor advisory with no CVSS in another
- exploit signals in a KEV-like catalog
- technical details in a Git repository or security advisory
- additional context from national or sector-specific feeds
If you only look at one source, you may miss the real picture.
GCVE and Vulnerability-Lookup are designed to preserve that wider context. The goal is not only to collect records, but to connect them. This gives defenders, coordinators, and analysts a better understanding of the vulnerability surface even when one authoritative source has not yet provided a complete enrichment.
Automation is no longer optional
Severity estimation is one of the clearest examples of a task that does not scale manually forever.
If a central program must choose where to spend human time, some records will inevitably remain unscored for some time, or indefinitely. Yet triage still has to happen. Operational teams still need a first estimate. Automation becomes the only realistic way to keep decision support available at scale.
This is where GCVE benefits directly from the automatic capabilities introduced in the broader ecosystem, especially through VL-AI.
VL-AI: automatic severity classification built from historical vulnerability data
VL-AI is a complete automatic system integrated in the Vulnerability-Lookup ecosystem to classify vulnerability severity from textual descriptions.
Rather than waiting for a manual score to appear somewhere upstream, VL-AI can provide an immediate machine-generated severity estimate based on patterns learned from historical data.
This is not a toy feature. It is the result of a practical engineering and research effort built on large real-world datasets.
As mentioned the published VLAI work and presentation material:
- the model was trained on historical vulnerability data
- it was fine-tuned on more than 600,000 real-world vulnerability records
- the main severity classification model reached an estimated accuracy of 82.89%
That does not mean it replaces expert analysis. It means it provides a fast, consistent, and operationally useful first-pass estimate when manual enrichment is unavailable, delayed, or incomplete.
In other words: exactly the kind of capability that becomes strategically important when public enrichment pipelines start focusing only on the highest-priority subset.
Why this is important for GCVE
The value of GCVE is not only that it supports distributed publication. It is also that it can be coupled with automated intelligence services that make distributed data more actionable.
This creates a stronger ecosystem:
- Distributed publication avoids a single point of operational saturation.
- Cross-source correlation preserves a broader view of each vulnerability.
- Automated severity estimation provides triage support even when no public manual score is available yet.
- Open APIs make these capabilities reusable by other tools and platforms.
This is a practical answer to a practical problem.
If the ecosystem is entering a phase where some vulnerabilities will remain tracked but not fully enriched by central actors, then local and federated automation becomes essential. GCVE is well positioned for that future because it was never designed around the assumption that enrichment must come from only one place.
A public API is already available
These automatic capabilities are not just internal concepts. They are exposed through a public API.
A public endpoint is available on the official GCVE database at:
/vlai/severity-classification
This makes it possible to integrate automatic severity classification directly into external workflows, triage systems, dashboards, or enrichment pipelines.
Example:
curl -X 'POST' \
'https://db.gcve.eu/api/vlai/severity-classification' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"description": "An authentication bypass in the API component of Ivanti Endpoint Manager Mobile 12.5.0.0 and prior allows attackers to access protected resources without proper credentials via the API."
}'Example response:
{
"severity": "High",
"confidence": 0.82
}The exact confidence value depends on the input, but the operational idea is simple: when manual scoring is missing, delayed, or deprioritized, defenders can still obtain a fast first estimate.
Open, reusable, and aligned with the real world
One of the strengths of the GCVE and Vulnerability-Lookup ecosystem is that these capabilities are developed in the open:
- open data
- open models
- open standard
- open APIs
- integration into operational workflows including MCP rather than isolated demos
That matters because vulnerability management is increasingly a data engineering problem as much as a coordination problem.
The challenge is no longer just assigning identifiers. The challenge is helping people make sense of a fast-growing, fragmented, and unevenly enriched body of vulnerability information.
Conclusion
NIST’s April 2026 decision is an important signal for the whole ecosystem. The era of guaranteed uniform enrichment for every vulnerability record is over.
That makes distributed systems, source correlation, and automation far more important than before.
GCVE was designed for exactly this kind of environment:
- distributed publication rather than central dependency
- global correlation across heterogeneous sources
- automatic capabilities such as VL-AI to keep triage possible at scale
The future of vulnerability intelligence will not be built on a single pipeline doing everything for everyone. It will be built on interoperable systems that share data, preserve context, and automate what must be automated.
GCVE is already moving in that direction.
Contact
For questions, feedback, or collaboration inquiries, please contact: info@gcve.eu or gna@gcve.eu if you want to become a GNA or announcing that you run an instance.